Introduction
Here we are, the last article of this serie. This one will cover the algorithms used to sort rows, and why OFFSET should be banned from your applications. 
Previously on the EXPLAIN show
- You learned that it all starts with logs
- You met the amazing pg_stat_statements
- You got to know a bit more about the life of a query, how
EXPLAINcan be used and what are costs and actual time in this episode - You understood (I hope!) the three types of scans
- And also you learned about how postgres joins tables
I hope that this made you want to look at the slides of the talk at the PgdayParis 2018. And I’ll post the video as soon as I have it. You can watch the short version from the djangoConEurope 2017.
Well here we go then !
Quicksort
Let’s order our humans by last_name.
owl_conference=# EXPLAIN ANALYZE SELECT * FROM human ORDER BY last_name;
QUERY PLAN
------------------------------------------------------------------------
Sort (cost=894.39..919.39 rows=10000 width=23)
(actual time=247.262..251.324 rows=10010 loops=1)
Sort Key: last_name
Sort Method: quicksort Memory: 1167kB
-> Seq Scan on human (cost=0.00..230.00 rows=10000 width=23)
(actual time=0.008..1.350 rows=10010 loops=1)
Planning time: 0.070 ms
Execution time: 252.504 ms
(6 rows)
Quicksort simply orders all rows in memory and return them ordered. For a big table it’s quite expensive in terms of memory. Here you can see that 1167kB were needed and it took 251.324ms (cf actual time for the Sort) which is quite a lot.
In this kind of situation you can wonder if you really need all of the rows…
So now let’s talk about LIMIT
Top-N heap sort
When you use ORDER BY ... LIMIT ..., you will end up with and EXPLAIN that looks like this.
owl_conference=# EXPLAIN ANALYZE SELECT * FROM human
ORDER BY last_name LIMIT 3;
QUERY PLAN
---------------------------------------------------------------------------------
Limit (cost=359.25..359.26 rows=3 width=23)
(actual time=17.726..17.727 rows=3 loops=1)
-> Sort (cost=359.25..384.25 rows=10000 width=23)
(actual time=17.725..17.726 rows=3 loops=1)
Sort Key: last_name
Sort Method: top-N heapsort Memory: 25kB
-> Seq Scan on human
(cost=0.00..230.00 rows=10000 width=23)
(actual time=0.054..3.186 rows=10010 loops=1)
Planning time: 0.271 ms
Execution time: 17.775 ms
(7 rows)
Here you can see several things:
- The memory used drops from 1167kB to 25kB
- The execution time is much lower
- It’s using a mysterious sort method called
top-N heapsort
The algorithm for a top-N heapsort is the following:
- A heap (a type of tree) is used with a limited size
- For each row
- If the heap isn’t full: add row in heap
- Else - If the value is smaller than the current values (for ASC): insert row in heap, pop last - Else pass
To make it more understandable, here are the first rows of my human table and a drawing of the first iterations.
| id | last_name |
|---|---|
| 1 | Potter |
| 2 | Bailey |
| 3 | Acosta |
| 4 | Weasley |
| 5 | Caroll |
| … | … |
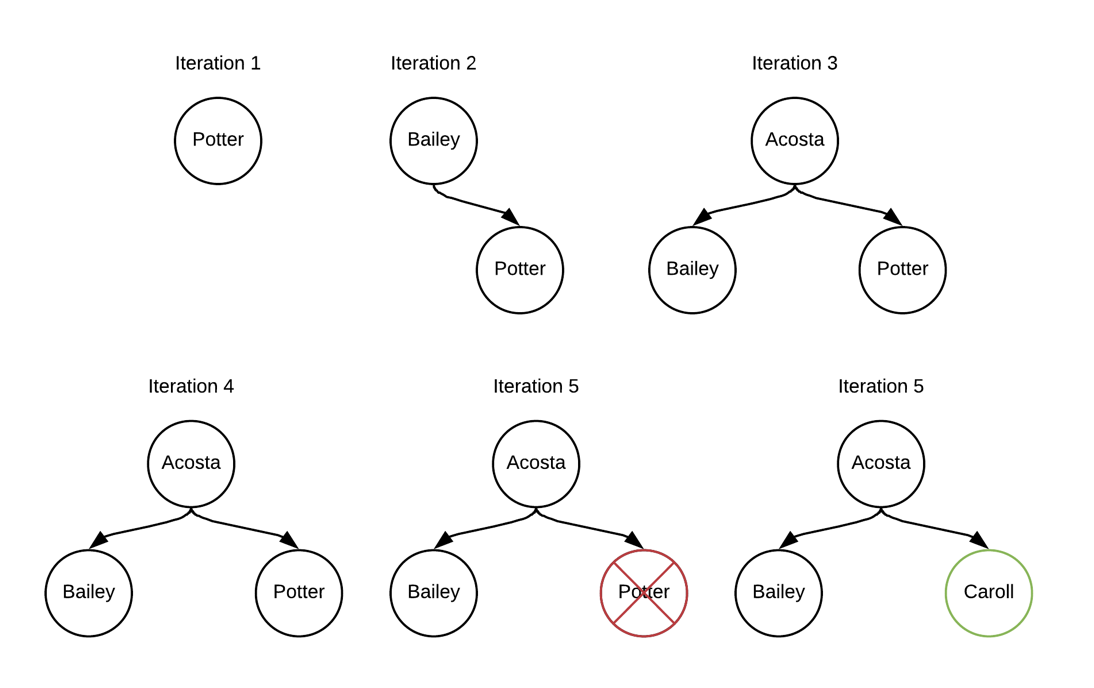
- The first three iterations simply fill up the tree
- The 4th iteration compares the value
Weasleyto the ones in the tree, it’s “bigger” than all of them, the row is skipped - The fifth iteration compares
Caroll, as it’s “smaller” thanPotter,Potteris removed from the tree and the row forCarollin inserted in the heap. - … It continues like this till the end of your table
This example is of course for a ASC order.
To avoid doing top-N heapsort, we can add an index on the order by column.
CREATE INDEX ON human (last_name);
owl_conference=# EXPLAIN ANALYZE SELECT * FROM human
ORDER BY last_name LIMIT 3;
QUERY PLAN
-----------------------------------------------------------------
Limit (cost=0.29..0.54 rows=3 width=23)
(actual time=0.086..0.090 rows=3 loops=1)
-> Index Scan using human_last_name_idx on human
(cost=0.29..838.42 rows=10010 width=23)
(actual time=0.086..0.089 rows=3 loops=1)
Planning time: 0.336 ms
Execution time: 0.105 ms
(4 rows)
So now it’s using the order of the index. Quick and nice !
A word on offset
Ordering is often used in order to paginate results. So it’s a good time to talk about OFFSET.
Let’s first create an index like previously:
CREATE INDEX ON letters (delivered_by);
Let’s look at the EXPLAIN of retrieving the first 10 rows out of my letters table.
owl_conference=# EXPLAIN ANALYZE SELECT * FROM letters
ORDER BY delivered_by DESC OFFSET 0 LIMIT 10;
QUERY PLAN
------------------------------------------------------------------
Limit (cost=0.42..1.02 rows=10 width=24)
(actual time=0.028..0.067 rows=10 loops=1)
-> Index Scan Backward using letters_delivered_by_idx on letters
(cost=0.42..24532.28 rows=413861 width=24)
(actual time=0.027..0.064 rows=10 loops=1)
Planning time: 0.105 ms
Execution time: 0.115 ms
(4 rows)
Oh nice, the execution time is under a millisecond, it’s using my index. Offset is awesome no?
Okay, now let’s try to retrieve rows at the page 40001, so with an offset of 400000 * 10 = 400000.
owl_conference=# EXPLAIN ANALYZE SELECT * FROM letters
ORDER BY delivered_by DESC OFFSET 400000 LIMIT 10;
QUERY PLAN
-------------------------------------------------------------------------
Limit (cost=23710.66..23711.25 rows=10 width=24)
(actual time=881.710..881.718 rows=10 loops=1)
-> Index Scan Backward using letters_delivered_by_idx on letters
(cost=0.42..24532.28 rows=413861 width=24)
(actual time=0.013..854.924 rows=400010 loops=1)
Planning time: 0.106 ms
Execution time: 654.810 ms
(4 rows)
Now it takes 654ms, and what you can see rows=400010. You only wanted 10 rows, so why is it fetching the 400 000 first ?
OFFSET is used to skip the first N rows of a query. But to do that the database must still fetch the rows and order them to return the last ones.
The good news is that you can live without OFFSET, here is a wonderful article on the subject.
Conclusion
Keep in mind that ordering can be a reason of a slow query, especially if you are ordering a big table, all rows, without indexes. If you are doing that, maybe you should look into why you need this and how you could change your application to have better performances.
And avoid OFFSET… It’s the worst, I know that most ORMs use it to paginate, but keep in mind that there are alternatives, like paginating by key, and libraries exist, like django infinite pagination.
So here you are. You have finished reading this series of articles on EXPLAIN, congratulations, I hope that you enjoyed them and will use EXPLAIN more often :) !